Research Articles

Benchmarking Pharmacophore Virtual Screening Against High-Throughput Screening: A Practical Guide for Modern Drug Discovery
This article provides a comprehensive benchmark comparison between pharmacophore-based virtual screening (PBVS) and high-throughput screening (HTS) for researchers and drug development professionals.
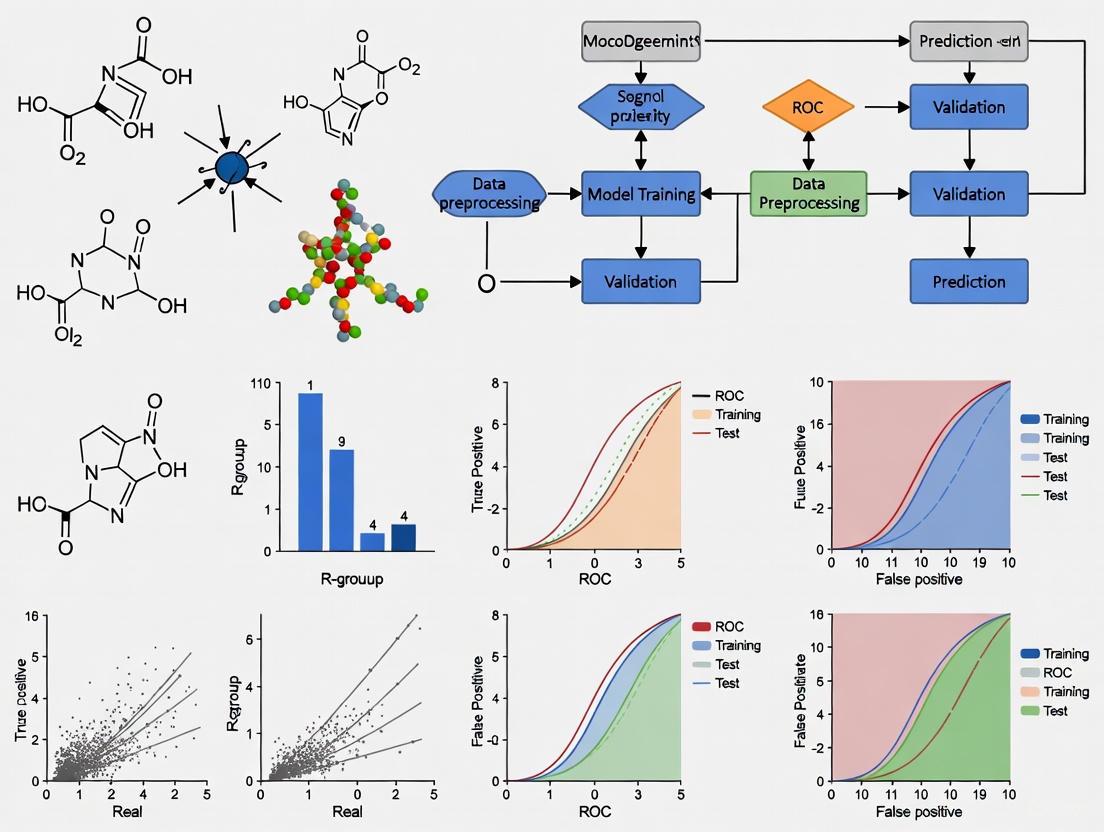
ROC Curve Analysis for Pharmacophore Model Validation: A Comprehensive Guide for Drug Discovery
This article provides a comprehensive guide for researchers and drug development professionals on applying Receiver Operating Characteristic (ROC) curve analysis to evaluate pharmacophore model performance.
Beyond Static Snapshots: Validating Pharmacophore Models with Molecular Dynamics Simulations for Robust Drug Discovery
This article provides a comprehensive guide for researchers and drug development professionals on integrating Molecular Dynamics (MD) simulations into the pharmacophore model validation pipeline.
Optimizing Pharmacophore Model Sensitivity: A Comprehensive Guide for Enhanced Virtual Screening
This article provides a systematic guide for researchers and drug development professionals on optimizing pharmacophore model sensitivity—a critical parameter for successful virtual screening.
Beyond Static Models: Mastering Conformational Sampling for Advanced Pharmacophore Modeling in Drug Discovery
This article addresses the critical challenge of conformational sampling in pharmacophore modeling, a cornerstone of modern computer-aided drug discovery.
A Comprehensive Guide to Pharmacophore-Based Virtual Screening for Neurodegenerative Disease Targets
This article provides a comprehensive overview of pharmacophore-based virtual screening (PBVS) protocols specifically tailored for neurodegenerative disease (NDD) targets.
Virtual Screening of Natural Product Databases: A Modern Protocol for Accelerating Drug Discovery
This article provides a comprehensive guide for researchers and drug development professionals on establishing a robust virtual screening protocol for natural product databases.
Pharmacophore Virtual Screening: Accelerating Lead Identification in Modern Drug Discovery
Pharmacophore-based virtual screening (VS) has evolved into a cornerstone strategy for efficient lead identification in drug discovery.
Comprehensive Pharmacophore-Based Virtual Screening Protocol for Kinase Inhibitors: From AI-Driven Design to Experimental Validation
This article provides a comprehensive guide to pharmacophore-based virtual screening (PBVS) for kinase inhibitor discovery, a critical methodology for addressing challenges like selectivity and resistance in oncology drug development.

Structure-Based vs. Ligand-Based Pharmacophore Modeling: A Comprehensive Guide for Drug Discovery
This article provides a detailed comparative analysis of structure-based and ligand-based pharmacophore modeling, two pivotal computational strategies in modern drug discovery.